
Blog by Manjunath Sirur, Data Science Lead
Read: 5 min
Introduction
A surprising number of AI programs stall for the same reason. The model works well enough in a demo, but the organization cannot answer the harder production questions. What happens when the system fabricates an answer? Who approves higher-risk use cases? How do teams trace which data informed an output? What evidence exists for auditors, risk teams, or business owners?
That is where many leaders misread guardrails. They see them as friction introduced after the exciting part is over. In reality, guardrails are what separate an interesting AI experiment from an enterprise capability. Frameworks from NIST, evolving policy support around the EU AI Act, and sector-specific regulatory guidance all point in the same direction: trustworthy AI depends on risk management, lifecycle control, transparency, and governance built into deployment, not bolted on after launch.
Guardrails only feel restrictive when AI is still being treated like a pilot
In early experimentation, almost any control looks like a delay. Teams want quick wins, lightweight approvals, and freedom to test prompts, models, and use cases. That instinct is understandable. But scale introduces a different set of realities: shared data access, cross-functional accountability, customer-facing use cases, model drift, inconsistent outputs, and rising scrutiny from security and compliance stakeholders.
The problem is not that guardrails slow innovation. The problem is that without them, every new use case becomes a custom risk negotiation. Teams recreate approval logic, invent ad hoc validation steps, and spend more time defending AI than improving it. That is not agility. It is fragile progress disguised as speed.
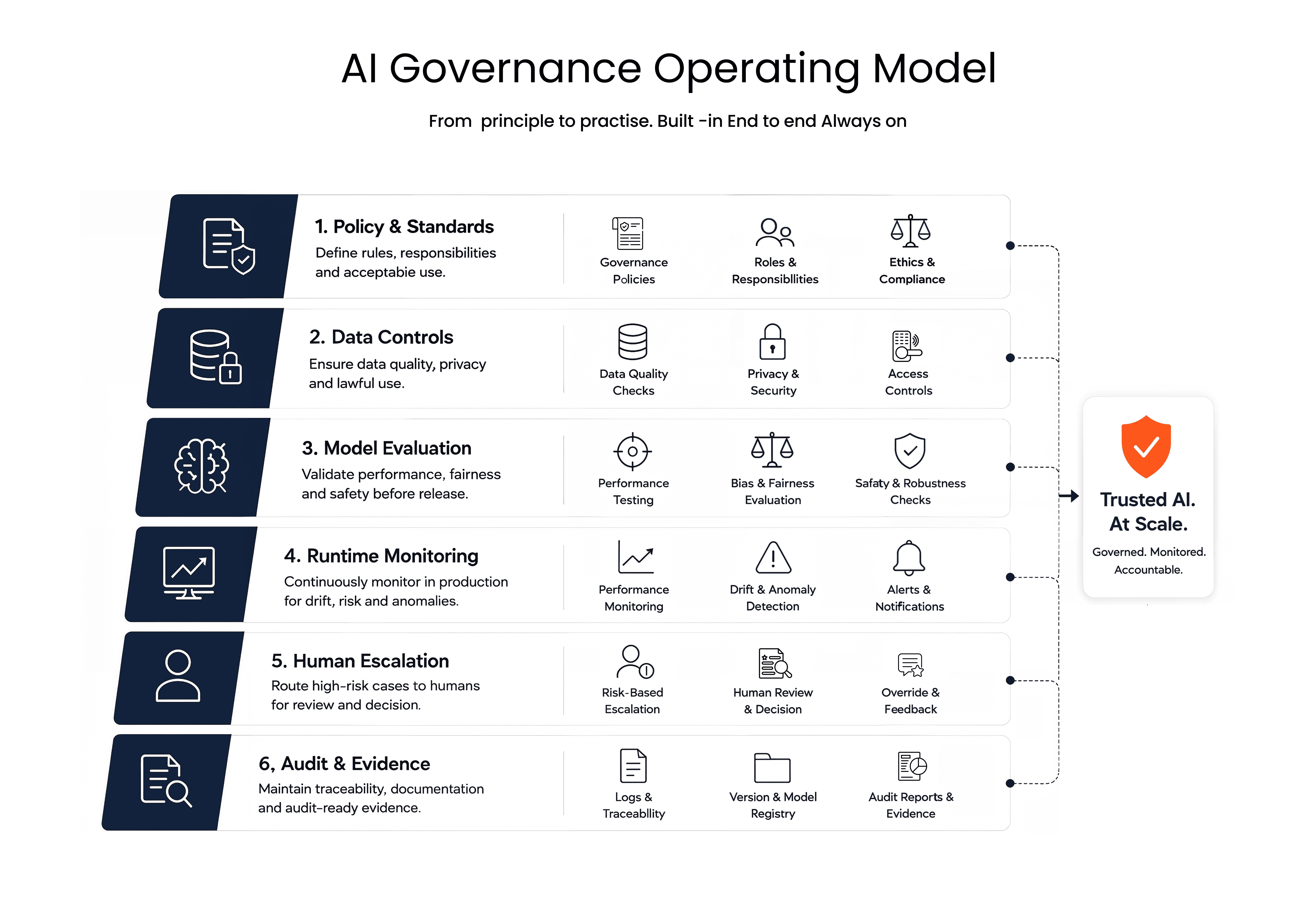
What scalable guardrails actually do
Good guardrails are not a single policy document or a content filter on top of an LLM. They are a system of controls that shape how AI is designed, tested, deployed, and supervised in production. Stronger market thinking is moving in this direction, with emphasis on policy-aware engineering, audit trails, validation, and role-specific human oversight.
They define where AI can act autonomously and where escalation is required.
They connect outputs to evidence through lineage, evals, and logging.
They translate governance from principle into repeatable delivery practice.
Hallucination control is an architecture problem, not only a model problem
Hallucination is often discussed as if it were just a model-quality issue. That is too narrow. In enterprise settings, hallucination control depends on grounding, access design, retrieval quality, workflow constraints, confidence thresholds, fallback paths, and monitoring. A better model helps, but it does not eliminate the need for system-level controls.
This matters because the business risk is rarely evenly distributed. A weak answer in an internal knowledge assistant may be manageable. A weak answer in a claims workflow, patient support journey, underwriting context, or regulated customer communication is something else entirely. In healthcare, scrutiny around clinical reliability and data provenance is growing precisely because the consequences of confident error are high.
The more useful enterprise question is not, “Can the model hallucinate?” It can. The better question is, “What have we built around the model so that hallucinations are detected, contained, and prevented from becoming business events?”
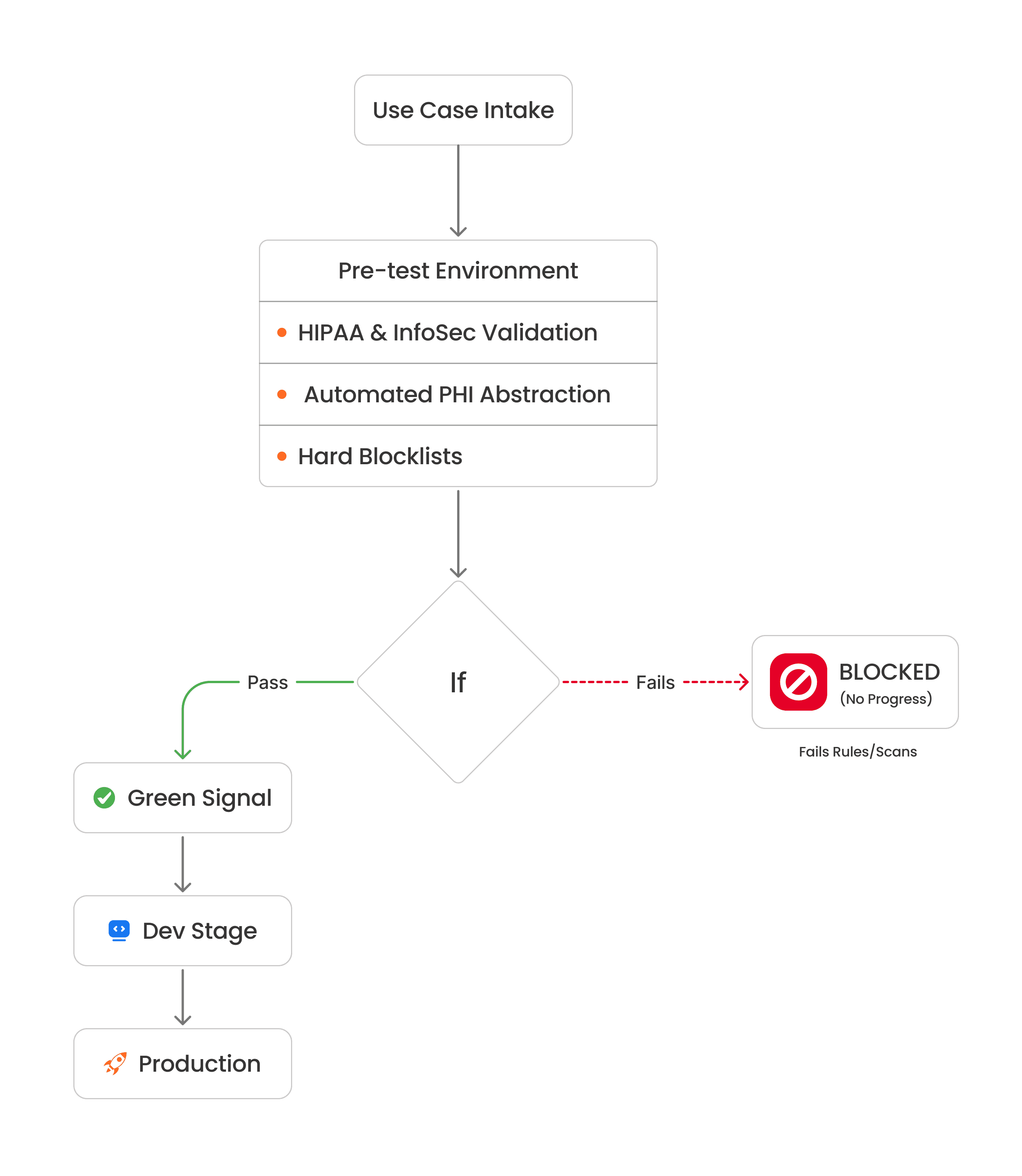
Case in Point: De-risking AI for Healthcare Research
To see what this looks like in practice, consider how we enabled a secure, GPT-like generative AI environment for a healthcare client's research teams. In medical research, the stakes for data privacy and intellectual property are exceptionally high. Moving straight from an experimental pilot to development wasn't an option; we needed a rigorous, repeatable mechanism to satisfy strict HIPAA compliance and intense InfoSec scrutiny.
Our solution was to architect a mandatory, isolated Pre-Test Environment that acts as an operational staging ground and strict compliance gateway for onboarding new AI use cases.
Instead of debating risk abstractly, research teams deploy their workflows into this pre-test sandbox where we systematically measure outcomes against enterprise guardrails. A critical component of this phase is automated Protected Health Information (PHI) abstraction. Before data interacts with the core LLM orchestration layers, the system automatically detects, isolates, and abstracts patient identifiers—replacing sensitive real-world metrics with structured tokens or synthesized data.
To ensure this abstraction layer works flawlessly and infrastructure boundaries are maintained, the environment enforces a strict, multi-layered validation process:
Deep Log Auditing: Every single system and user log is read and analyzed to track data lineage and ensure no leaked PHI accidentally bypassed the abstraction filters.
Database & Storage Scanning: All backend databases are scanned to verify that data is strictly stored in its abstracted, compliant state and no raw PHI is exposed.
Client-Server Data Auditing: Both browser-side cached data and server-stored data are thoroughly scanned for hidden vulnerabilities, leakage, or un-abstracted strings.
Network & Perimeter Enforcement: The environment validates that all traffic strictly routes through corporate VPN architectures, blocking any shadow IT endpoints.
The Automated Fail-Safe: Hard Blocklists.
If a use case fails to comply with even a single InfoSec or HIPAA rule during this phase, it is completely blocked from moving forward. It cannot advance to the development stage, let alone production. We enforce these boundaries through strict architectural blocklists, for example:
Model Restrictions: When a research workflow was stitched together using DeepSeek, the system automatically blacklisted the deployment due to corporate compliance non-adherence. Similarly, any models originating from high-risk regions, such as Russia, are hard-blocked at the gateway level.
Geographic & Cloud Restrictions: The system actively scans the backend orchestration to ensure data isn't being routed through unapproved cloud providers or unauthorized geographic regions.
Only when a use case receives a flawless, formal green signal across all network, model, and compliance checks in this pre-test environment is it permitted to progress to the standard development stage and eventual production.
By turning PHI abstraction and compliance into a concrete, automated gateway rather than a bureaucratic bottleneck, we gave research teams the freedom to innovate with advanced AI while giving risk and compliance stakeholders total peace of mind. This is how governance moves from an abstract constraint to an industrial scale enabler.
Governance should increase delivery speed, not reduce it
The strongest AI organizations are not the ones with the fewest controls. They are the ones that have converted controls into reusable delivery assets. Standard evaluation pipelines. Approved model patterns. Data access rules. Human review thresholds. Incident response playbooks. Audit-ready logs. Once these exist, teams stop debating first principles for every new deployment and start shipping within a known operating boundary.
That is the real value of guardrails. They reduce uncertainty, compress approval cycles, and create consistency across teams. They also give leadership something equally important: visibility into which AI systems are reliable enough to scale, which ones need tighter oversight, and which ones should never move beyond experimentation. That is what turns responsible AI from a governance topic into a growth enabler.

Fig: AI Governance: Right Controls for the Right Context
Conclusion:
AI guardrails are not what stop enterprises from scaling AI. They are what stop AI scaling from breaking down under its own risk, inconsistency, and operational ambiguity.
For enterprise leaders, the next phase of AI adoption is not about choosing between speed and control. It is about building the kind of governance, evaluation, and oversight that lets speed survive contact with the real world. In regulated industries especially, that distinction matters. The organizations that win will not be the ones that moved fastest in the pilot stage. They will be the ones that built AI systems others can trust, audit, and expand.