
From Pass/Fail Testing to AI Quality Engineering: LLM Metrics QA Teams Need
From Pass/Fail Testing to AI Quality Engineering: LLM Metrics QA Teams Need
Sidhanath Verekar, Associate Software Engineer
Read: 5 min
Introduction
Most QA systems were built to catch deterministic failure: a broken API contract, a failed assertion, a UI flow that stops midway, or a calculation that returns the wrong value. These failures still matter. But AI-enabled software adds a different kind of risk. The system may work technically and still fail operationally. A banking assistant can explain a policy in confident language while missing a regulatory condition. A healthcare summarization tool can preserve the structure of a clinical note while changing its meaning. A travel assistant can answer a refund question quickly, but from the wrong fare rule. A loyalty chatbot may give a strong answer in one test and a weaker one when the same request is phrased differently. That is why QA for LLM applications needs more than pass/fail assertions. It needs a measurement model for systems that generate, retrieve, reason, and vary across prompts. LLM evaluation metrics give quality teams that model. They help teams measure whether an AI system is accurate, relevant, grounded, safe, performant, and stable enough to be trusted in production.
AI Changes What QA Has To Prove
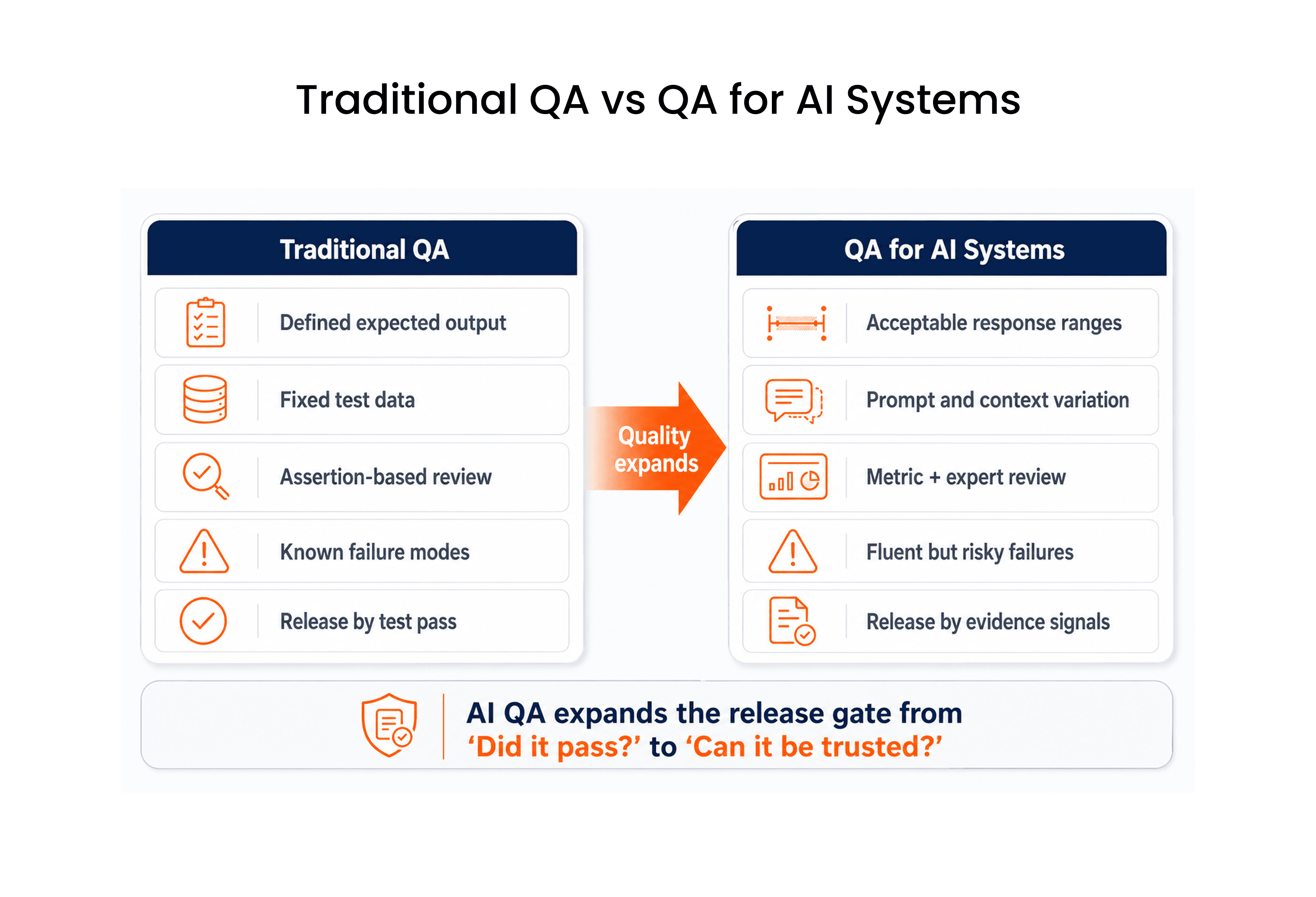
Traditional QA assumes that expected behavior can be defined in advance. For many application flows, that remains true. A payment should succeed or fail based on known rules. A booking should generate a confirmation number. A claim submission should follow a defined workflow. LLM-powered features introduce another layer. The system may produce natural-language output, retrieve context from enterprise data, call external tools, summarize a record, classify intent, or recommend the next action. The result is not always a single expected value. It may be a range of acceptable responses with different levels of completeness, usefulness, and risk. For QA teams, quality now has to be evaluated across three layers:
Response quality: Is the answer correct, relevant, complete, and usable?
Evidence quality: Is the answer grounded in the right source data or retrieved context?
Operational quality: Is the system fast, safe, observable, and stable across releases?
This is where LLM evaluation becomes a quality engineering discipline, not just a data science exercise. The goal is not to score a model in isolation. The goal is to decide whether an AI-enabled workflow can be trusted by users, operators, regulators, and the business.
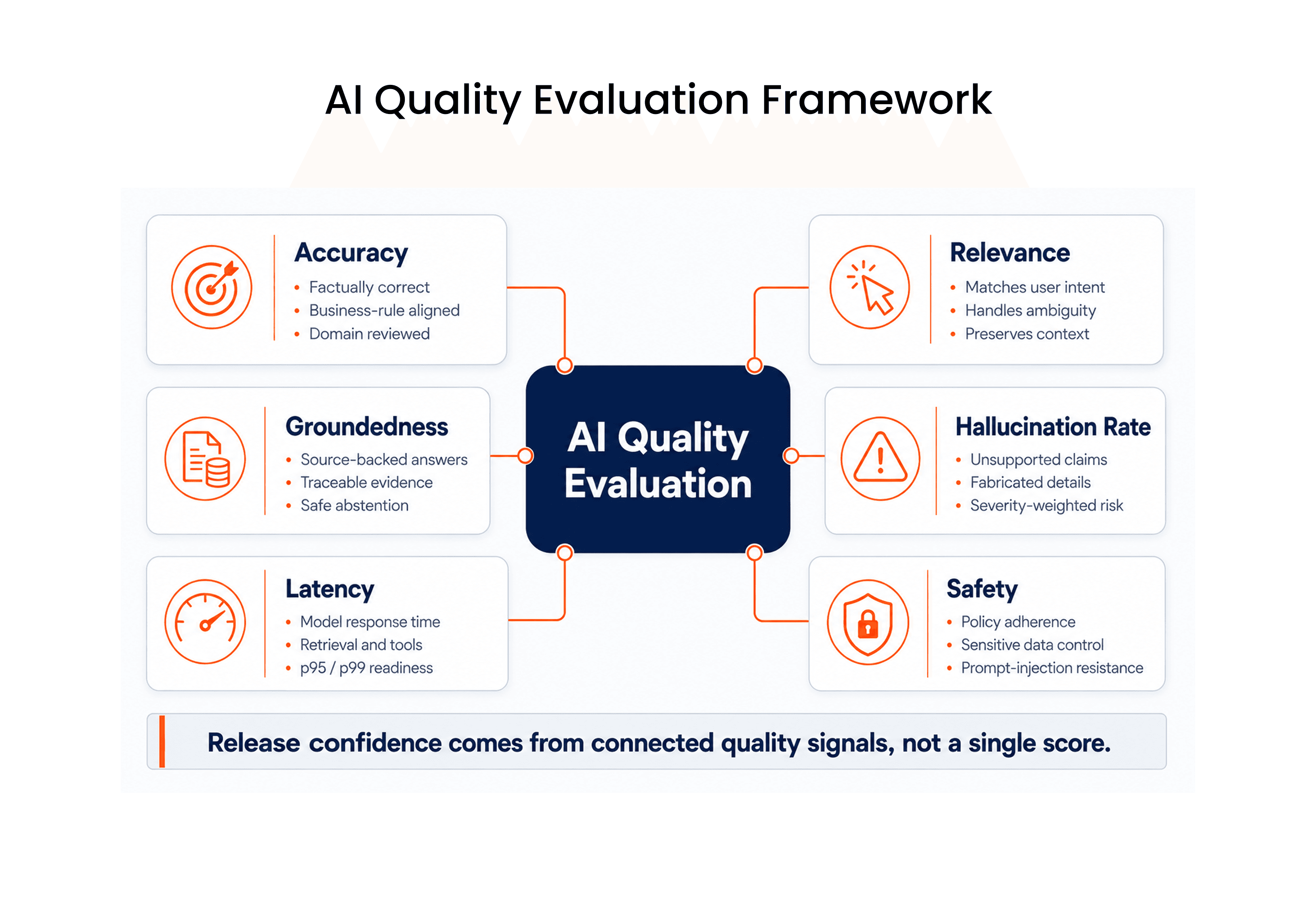
The Six LLM Evaluation Metrics That Matter
LLM evaluation should not become a disconnected dashboard of model scores. Each metric should answer a release-readiness question. Can the response be trusted? Did it answer the real intent? Is it supported by evidence? Did it invent anything? Is it fast enough for the workflow? Does it stay within policy and risk boundaries? The most useful QA programs treat these metrics as connected signals, not isolated numbers.
Accuracy: Can The Response Be Trusted As Fact?
Accuracy is where many AI applications create false confidence. A response can sound complete, cite the right topic, and still miss the policy condition, clinical detail, fare rule, or eligibility threshold that makes the answer safe to use. A traditional test might check whether an API returns the expected status code. An LLM accuracy test may need to verify whether the answer reflects the correct policy, calculation, account rule, clinical detail, fare condition, or product attribute. In a BFSI use case, an assistant explaining loan eligibility cannot invent thresholds or omit mandatory conditions. In healthcare, an AI-generated summary cannot alter clinical meaning. In travel and hospitality, a support assistant cannot misstate cancellation rules, loyalty benefits, or refund eligibility. QA teams should evaluate accuracy through:
Golden datasets: Curated prompts with expected facts, acceptable answer ranges, and known edge cases.
Domain review: Expert validation for regulated or high-risk workflows.
Regression baselines: Re-running the same evaluation sets after model, prompt, retrieval, or application changes.
Accuracy should not be treated as a generic score. It should be tied to business risk. A slightly incomplete hotel recommendation may be tolerable. An incorrect medication instruction, payment rule, or fraud escalation response is not.
Relevance: Did The System Understand The Real Intent?
Relevance measures whether the response addresses the user’s actual intent. An answer can be accurate and still fail if it solves the wrong problem. Consider a loyalty member asking why points from a hotel stay were not credited. A generic explanation of the loyalty program may be factually correct, but it is not relevant. The answer should respond to the transaction, partner rules, eligibility window, posting delay, or escalation path. This becomes harder in multi-turn conversations. A system may answer the first question correctly, then lose context when the user adds a constraint, changes the request, or asks a follow-up. QA teams should test relevance across real user-intent patterns:
Direct intent: Does the response answer the specific question?
Ambiguous intent: Does the system ask for clarification instead of guessing?
Multi-turn intent: Does the system preserve the right context across the conversation?
For QA engineers, relevance testing is where prompt variation matters. Users rarely ask questions in clean test-case language. They ask with missing details, shorthand, emotional wording, or mixed intent. The evaluation set should reflect that reality.
Groundedness: Is The Answer Supported By Evidence?
Groundedness measures whether the answer is supported by the source material available to the system. This is critical for retrieval-augmented generation, where the LLM is expected to answer using enterprise documents, knowledge bases, policies, records, or transactional data. A grounded answer is not merely plausible. It is traceable. In a banking assistant, the response should reflect the policy, disclosure, or customer record retrieved for that question. In a healthcare workflow, the summary should align with the source note or structured record. In an airline servicing flow, the answer should match the fare rule, booking status, disruption policy, or loyalty profile actually available to the system. Groundedness failures can be subtle. The system may retrieve the right document but misinterpret it. It may cite a real source but draw a conclusion the source does not support. It may answer from general model knowledge when it should rely only on enterprise context. QA teams should evaluate:
Retrieval quality: Did the system fetch the right source material?
Answer faithfulness: Did the final response accurately reflect that material?
Abstention behavior: Did the system avoid answering when evidence was missing?
Groundedness is especially important in regulated industries because it supports auditability. If the business cannot trace why an answer was given, the answer may be difficult to trust, defend, or improve.
Hallucination Rate: How Often Does Confidence Hide Fabrication?
Hallucination rate measures how often the LLM produces unsupported, fabricated, or misleading information. For QA teams, this is one of the most important AI failure modes because hallucinations often look polished. A hallucination may appear as a fake policy clause, an invented citation, an unsupported recommendation, a wrong calculation, or a confident answer when the system should say it does not know. The key challenge is measurement. Teams need to decide whether hallucination rate is calculated per response, per claim, per test case, or by severity. A minor unsupported phrase and a fabricated financial rule should not carry the same risk weight. A practical QA approach is to classify hallucinations by severity:
Low severity: Unsupported wording that does not change the business meaning.
Medium severity: Incorrect or unsupported information that may confuse the user.
High severity: Fabricated guidance that creates financial, safety, compliance, or customer-impact risk.
Hallucination testing should include missing-context prompts, adversarial prompts, edge cases, and scenarios where the correct behavior is escalation or abstention. The goal is not only to catch wrong answers. It is to test whether the system knows when not to answer.
Latency: Is The AI Experience Fast Enough For The Workflow?
Latency becomes a quality issue when AI sits inside a live workflow. A slow response does not just affect performance scores; it changes whether users trust the system enough to keep using it. A customer support chatbot that takes too long during flight disruption may technically work but still fail the customer journey. A fraud operations assistant that slows down analyst review may reduce productivity instead of improving it. A clinical documentation assistant that delays the provider’s workflow will struggle to gain adoption, even if the output is accurate. LLM latency has multiple layers:
Model latency: Time taken by the model to generate the response.
Retrieval latency: Time spent searching and ranking source content.
Tool latency: Time spent calling APIs, databases, or workflow systems.
End-to-end latency: What the user actually experiences.
QA teams should evaluate p50, p95, and p99 latency, not just average response time. AI systems often look acceptable in controlled testing but degrade under peak load, long prompts, complex retrieval, or multi-tool workflows. For industries such as airlines, retail, and BFSI, latency should be tested against business moments: peak booking demand, promotion traffic, payment flows, fraud review queues, claims spikes, and service disruption events.
Safety: Can The System Stay Within Policy And Risk Boundaries?
Safety evaluation measures whether the AI system avoids harmful, non-compliant, biased, sensitive, or policy-violating responses. In enterprise QA, safety is broader than toxic language. It includes privacy leakage, regulated advice, insecure instructions, prompt injection, jailbreak attempts, and inappropriate tool use. A healthcare assistant must not expose protected health information. A banking assistant must not provide unauthorized financial advice or bypass identity verification. A travel assistant must not mishandle payment information, identity data, or crisis-response communication. Safety testing should include both expected and adversarial behavior. Users may ask direct questions, but they may also attempt to override instructions, request sensitive data, manipulate the system, or push it outside approved boundaries. QA teams should test for:
Policy adherence: Does the system follow business and regulatory rules?
Sensitive data handling: Does it avoid exposing protected or restricted information?
Prompt-injection resistance: Does it maintain controls when users attempt to bypass them?
Safety is where AI testing must connect closely with security, compliance, and governance. A response that is accurate and relevant can still be unacceptable if it violates policy. Not Every Metric Should Carry The Same Weight LLM evaluation becomes more useful when teams connect metrics to workflow risk. A retail product recommendation can tolerate a wider range of acceptable answers than a banking policy explanation, healthcare summary, or fraud escalation response. The question is not only “What did the model score?” The better question is “Which failures would block release, which require human review, and which should be monitored after launch?”
QA leaders should define:
Release gates: Metrics that must meet a threshold before production.
Review triggers: Scenarios that require domain, compliance, or security review.
Monitoring signals: Metrics that should be tracked continuously after launch.
This is also where ownership matters. QA cannot evaluate AI behavior alone. Product teams understand user intent. Domain experts understand business meaning. Data teams understand source quality. Security and compliance teams understand risk boundaries. Strong AI QA brings these perspectives into one evaluation model. From LLM Evaluation To AI-Augmented Quality Engineering LLM evaluation metrics help teams measure AI behavior, but they do not solve the broader delivery problem by themselves. AI is changing not only what teams build, but how quickly they build it. AI coding tools can increase pull request volume, accelerate feature delivery, and expand the amount of code touching interconnected systems. That creates a second quality challenge: regression risk can rise faster than traditional QA cycles can absorb.This is the operating model shift QA leaders need to plan for. AI quality now has two layers:
AI behavior quality: Are LLM responses accurate, relevant, grounded, safe, and performant?
AI delivery quality: Can the application absorb faster AI-assisted development without increasing escaped defects, brittle regression suites, or release uncertainty?
AI Changes What QA Has To Prove
Traditional QA assumes that expected behavior can be defined in advance. For many application flows, that remains true. A payment should succeed or fail based on known rules. A booking should generate a confirmation number. A claim submission should follow a defined workflow. LLM-powered features introduce another layer. The system may produce natural-language output, retrieve context from enterprise data, call external tools, summarize a record, classify intent, or recommend the next action. The result is not always a single expected value. It may be a range of acceptable responses with different levels of completeness, usefulness, and risk. For QA teams, quality now has to be evaluated across three layers:
Response quality: Is the answer correct, relevant, complete, and usable?
Evidence quality: Is the answer grounded in the right source data or retrieved context?
Operational quality: Is the system fast, safe, observable, and stable across releases?
This is where LLM evaluation becomes a quality engineering discipline, not just a data science exercise. The goal is not to score a model in isolation. The goal is to decide whether an AI-enabled workflow can be trusted by users, operators, regulators, and the business.
The Six LLM Evaluation Metrics That Matter
LLM evaluation should not become a disconnected dashboard of model scores. Each metric should answer a release-readiness question. Can the response be trusted? Did it answer the real intent? Is it supported by evidence? Did it invent anything? Is it fast enough for the workflow? Does it stay within policy and risk boundaries? The most useful QA programs treat these metrics as connected signals, not isolated numbers.
Accuracy: Can The Response Be Trusted As Fact?
Accuracy is where many AI applications create false confidence. A response can sound complete, cite the right topic, and still miss the policy condition, clinical detail, fare rule, or eligibility threshold that makes the answer safe to use. A traditional test might check whether an API returns the expected status code. An LLM accuracy test may need to verify whether the answer reflects the correct policy, calculation, account rule, clinical detail, fare condition, or product attribute. In a BFSI use case, an assistant explaining loan eligibility cannot invent thresholds or omit mandatory conditions. In healthcare, an AI-generated summary cannot alter clinical meaning. In travel and hospitality, a support assistant cannot misstate cancellation rules, loyalty benefits, or refund eligibility. QA teams should evaluate accuracy through:
Golden datasets: Curated prompts with expected facts, acceptable answer ranges, and known edge cases.
Domain review: Expert validation for regulated or high-risk workflows.
Regression baselines: Re-running the same evaluation sets after model, prompt, retrieval, or application changes.
Accuracy should not be treated as a generic score. It should be tied to business risk. A slightly incomplete hotel recommendation may be tolerable. An incorrect medication instruction, payment rule, or fraud escalation response is not.
Relevance: Did The System Understand The Real Intent?
Relevance measures whether the response addresses the user’s actual intent. An answer can be accurate and still fail if it solves the wrong problem. Consider a loyalty member asking why points from a hotel stay were not credited. A generic explanation of the loyalty program may be factually correct, but it is not relevant. The answer should respond to the transaction, partner rules, eligibility window, posting delay, or escalation path. This becomes harder in multi-turn conversations. A system may answer the first question correctly, then lose context when the user adds a constraint, changes the request, or asks a follow-up. QA teams should test relevance across real user-intent patterns:
Direct intent: Does the response answer the specific question?
Ambiguous intent: Does the system ask for clarification instead of guessing?
Multi-turn intent: Does the system preserve the right context across the conversation?
For QA engineers, relevance testing is where prompt variation matters. Users rarely ask questions in clean test-case language. They ask with missing details, shorthand, emotional wording, or mixed intent. The evaluation set should reflect that reality.
Groundedness: Is The Answer Supported By Evidence?
Groundedness measures whether the answer is supported by the source material available to the system. This is critical for retrieval-augmented generation, where the LLM is expected to answer using enterprise documents, knowledge bases, policies, records, or transactional data. A grounded answer is not merely plausible. It is traceable. In a banking assistant, the response should reflect the policy, disclosure, or customer record retrieved for that question. In a healthcare workflow, the summary should align with the source note or structured record. In an airline servicing flow, the answer should match the fare rule, booking status, disruption policy, or loyalty profile actually available to the system. Groundedness failures can be subtle. The system may retrieve the right document but misinterpret it. It may cite a real source but draw a conclusion the source does not support. It may answer from general model knowledge when it should rely only on enterprise context. QA teams should evaluate:
Retrieval quality: Did the system fetch the right source material?
Answer faithfulness: Did the final response accurately reflect that material?
Abstention behavior: Did the system avoid answering when evidence was missing?
Groundedness is especially important in regulated industries because it supports auditability. If the business cannot trace why an answer was given, the answer may be difficult to trust, defend, or improve.
Hallucination Rate: How Often Does Confidence Hide Fabrication?
Hallucination rate measures how often the LLM produces unsupported, fabricated, or misleading information. For QA teams, this is one of the most important AI failure modes because hallucinations often look polished. A hallucination may appear as a fake policy clause, an invented citation, an unsupported recommendation, a wrong calculation, or a confident answer when the system should say it does not know. The key challenge is measurement. Teams need to decide whether hallucination rate is calculated per response, per claim, per test case, or by severity. A minor unsupported phrase and a fabricated financial rule should not carry the same risk weight. A practical QA approach is to classify hallucinations by severity:
Low severity: Unsupported wording that does not change the business meaning.
Medium severity: Incorrect or unsupported information that may confuse the user.
High severity: Fabricated guidance that creates financial, safety, compliance, or customer-impact risk.
Hallucination testing should include missing-context prompts, adversarial prompts, edge cases, and scenarios where the correct behavior is escalation or abstention. The goal is not only to catch wrong answers. It is to test whether the system knows when not to answer.
Latency: Is The AI Experience Fast Enough For The Workflow?
Latency becomes a quality issue when AI sits inside a live workflow. A slow response does not just affect performance scores; it changes whether users trust the system enough to keep using it. A customer support chatbot that takes too long during flight disruption may technically work but still fail the customer journey. A fraud operations assistant that slows down analyst review may reduce productivity instead of improving it. A clinical documentation assistant that delays the provider’s workflow will struggle to gain adoption, even if the output is accurate. LLM latency has multiple layers:
Model latency: Time taken by the model to generate the response.
Retrieval latency: Time spent searching and ranking source content.
Tool latency: Time spent calling APIs, databases, or workflow systems.
End-to-end latency: What the user actually experiences.
QA teams should evaluate p50, p95, and p99 latency, not just average response time. AI systems often look acceptable in controlled testing but degrade under peak load, long prompts, complex retrieval, or multi-tool workflows. For industries such as airlines, retail, and BFSI, latency should be tested against business moments: peak booking demand, promotion traffic, payment flows, fraud review queues, claims spikes, and service disruption events.
Safety: Can The System Stay Within Policy And Risk Boundaries?
Safety evaluation measures whether the AI system avoids harmful, non-compliant, biased, sensitive, or policy-violating responses. In enterprise QA, safety is broader than toxic language. It includes privacy leakage, regulated advice, insecure instructions, prompt injection, jailbreak attempts, and inappropriate tool use. A healthcare assistant must not expose protected health information. A banking assistant must not provide unauthorized financial advice or bypass identity verification. A travel assistant must not mishandle payment information, identity data, or crisis-response communication. Safety testing should include both expected and adversarial behavior. Users may ask direct questions, but they may also attempt to override instructions, request sensitive data, manipulate the system, or push it outside approved boundaries. QA teams should test for:
Policy adherence: Does the system follow business and regulatory rules?
Sensitive data handling: Does it avoid exposing protected or restricted information?
Prompt-injection resistance: Does it maintain controls when users attempt to bypass them?
Safety is where AI testing must connect closely with security, compliance, and governance. A response that is accurate and relevant can still be unacceptable if it violates policy. Not Every Metric Should Carry The Same Weight LLM evaluation becomes more useful when teams connect metrics to workflow risk. A retail product recommendation can tolerate a wider range of acceptable answers than a banking policy explanation, healthcare summary, or fraud escalation response. The question is not only “What did the model score?” The better question is “Which failures would block release, which require human review, and which should be monitored after launch?”
QA leaders should define:
Release gates: Metrics that must meet a threshold before production.
Review triggers: Scenarios that require domain, compliance, or security review.
Monitoring signals: Metrics that should be tracked continuously after launch.
This is also where ownership matters. QA cannot evaluate AI behavior alone. Product teams understand user intent. Domain experts understand business meaning. Data teams understand source quality. Security and compliance teams understand risk boundaries. Strong AI QA brings these perspectives into one evaluation model. From LLM Evaluation To AI-Augmented Quality Engineering LLM evaluation metrics help teams measure AI behavior, but they do not solve the broader delivery problem by themselves. AI is changing not only what teams build, but how quickly they build it. AI coding tools can increase pull request volume, accelerate feature delivery, and expand the amount of code touching interconnected systems. That creates a second quality challenge: regression risk can rise faster than traditional QA cycles can absorb.This is the operating model shift QA leaders need to plan for. AI quality now has two layers:
AI behavior quality: Are LLM responses accurate, relevant, grounded, safe, and performant?
AI delivery quality: Can the application absorb faster AI-assisted development without increasing escaped defects, brittle regression suites, or release uncertainty?

Fig: Two-Layer AI Quality Model
Conclusion
LLM evaluation metrics give QA engineers a practical language for testing AI systems. Accuracy, relevance, groundedness, hallucination rate, latency, and safety each reveal a different kind of production risk. Together, they help teams move from subjective AI review to measurable AI quality. But the larger shift is that AI changes both the application and the delivery system. Teams are testing LLM-powered features while also managing AI-generated code, faster release cycles, and wider regression exposure.
For enterprises building AI-enabled products, modernizing legacy platforms, or scaling AI-assisted development, quality engineering can no longer remain a final checkpoint. It has to become an orchestration layer across the SDLC. The goal is not only to test whether AI responds. It is to prove whether the system can be trusted, released, monitored, and improved at the speed modern engineering now requires
Join our newsletter.
Smart reads, bold ideas and what’s next sent to you.
Resources
Join our newsletter.
Smart reads, bold ideas and what’s next sent to you.
Resources
Join our newsletter.
Smart reads, bold ideas and what’s next sent to you.
Resources